字形混淆:浏览器里的攻与防
免责声明:本文以及文中涉及的代码仅用于个人学习交流,禁止转载。同时请勿将本文介绍的相关技术用于非法用途,对于非法用途或者滥用相关技术而产生的风险和相关的法律后果,与本文作者无关。请在阅读本文内容时,确保仅用于个人学习交流,并遵守当地法律法规。
故事的开始
不知道大家有没有用过一些剪藏助手的浏览器插件,就可以把在网页上看到内容,通过插件将内容收藏起来。我自己平时就会把这些自己觉得有收藏价值的内容,通过印象笔记、金山文档等剪藏助手收藏起来,供以后翻看。
但是前段时间,在剪藏一篇文章时,发现了一个奇怪的事情。我打开了一个网站,这个网站是讲历史的,在拿出我的剪藏助手想要收藏时,遇到了下面的问题。这里我随便找一篇这个网站的文章作为例子截图演示一下:
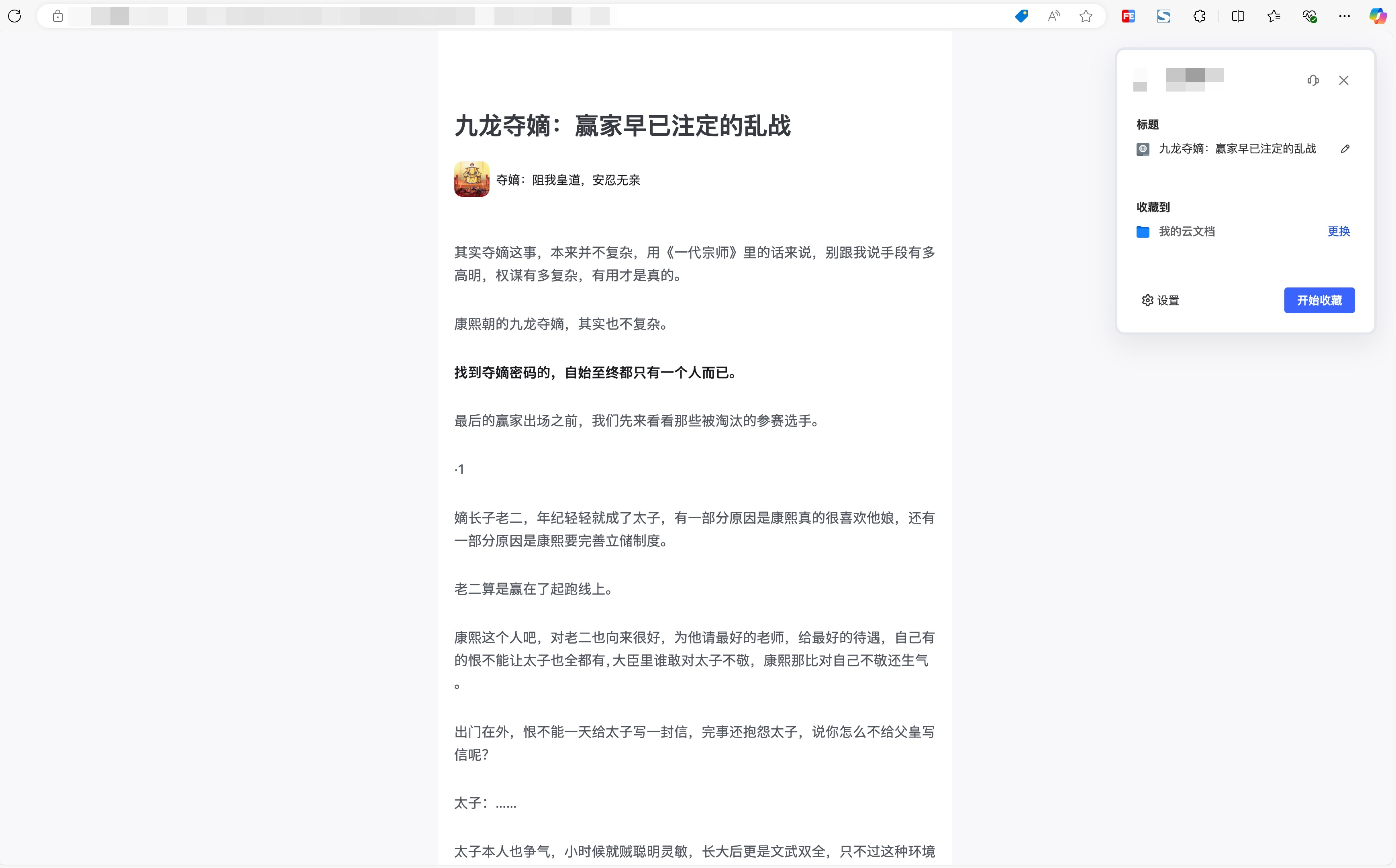
但是剪藏完之后一看,发现不对的地方了,怎么句子都读不通顺?难道剪藏助手出bug了?

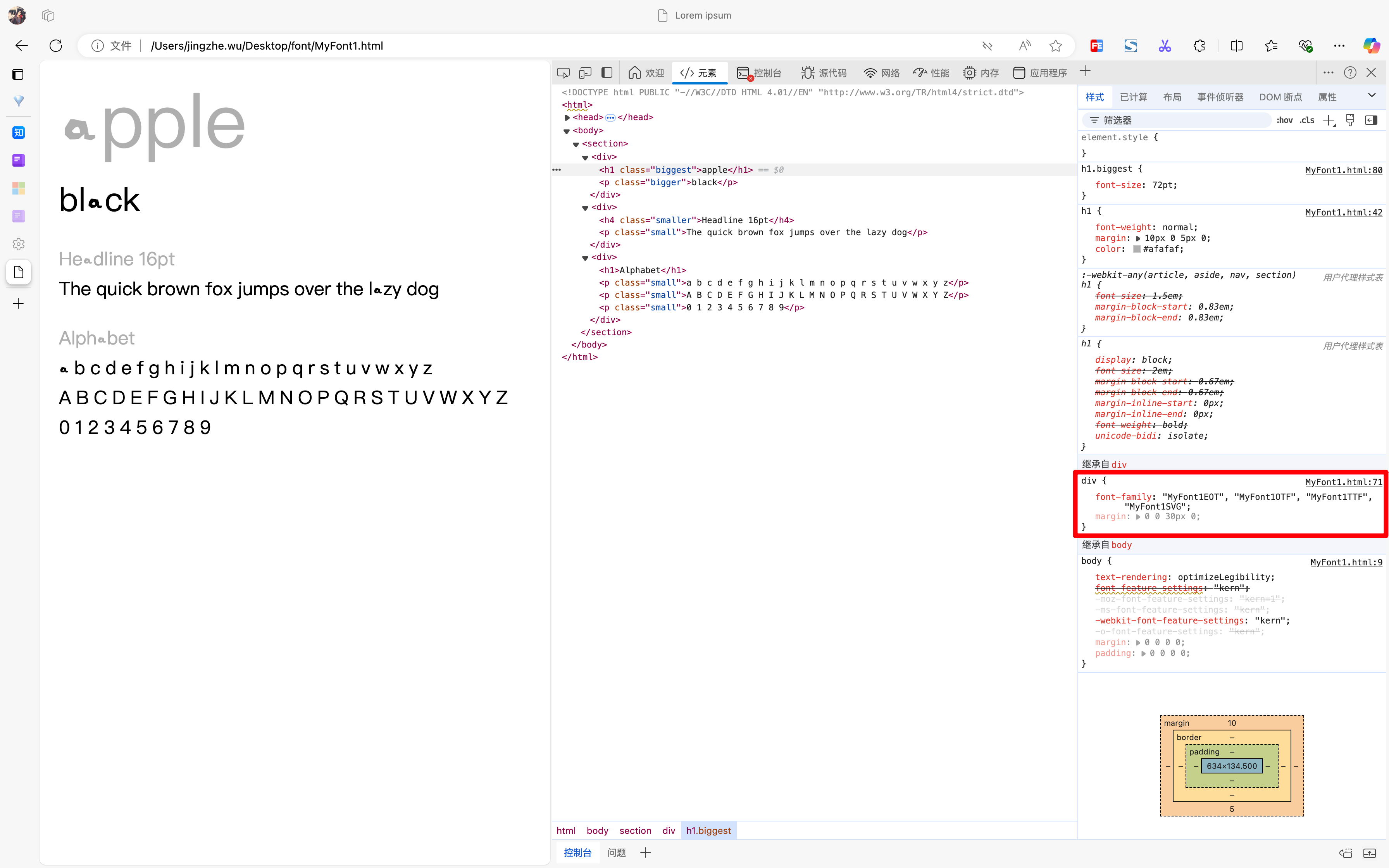
要知道,所谓的剪藏助手,它的原理就是读取网页的HTML,把里面的文字和样式获取到然后塞到自己新创建的文档里,正常来讲不应该有问题的。打开这个网站浏览器开发者工具看一下:
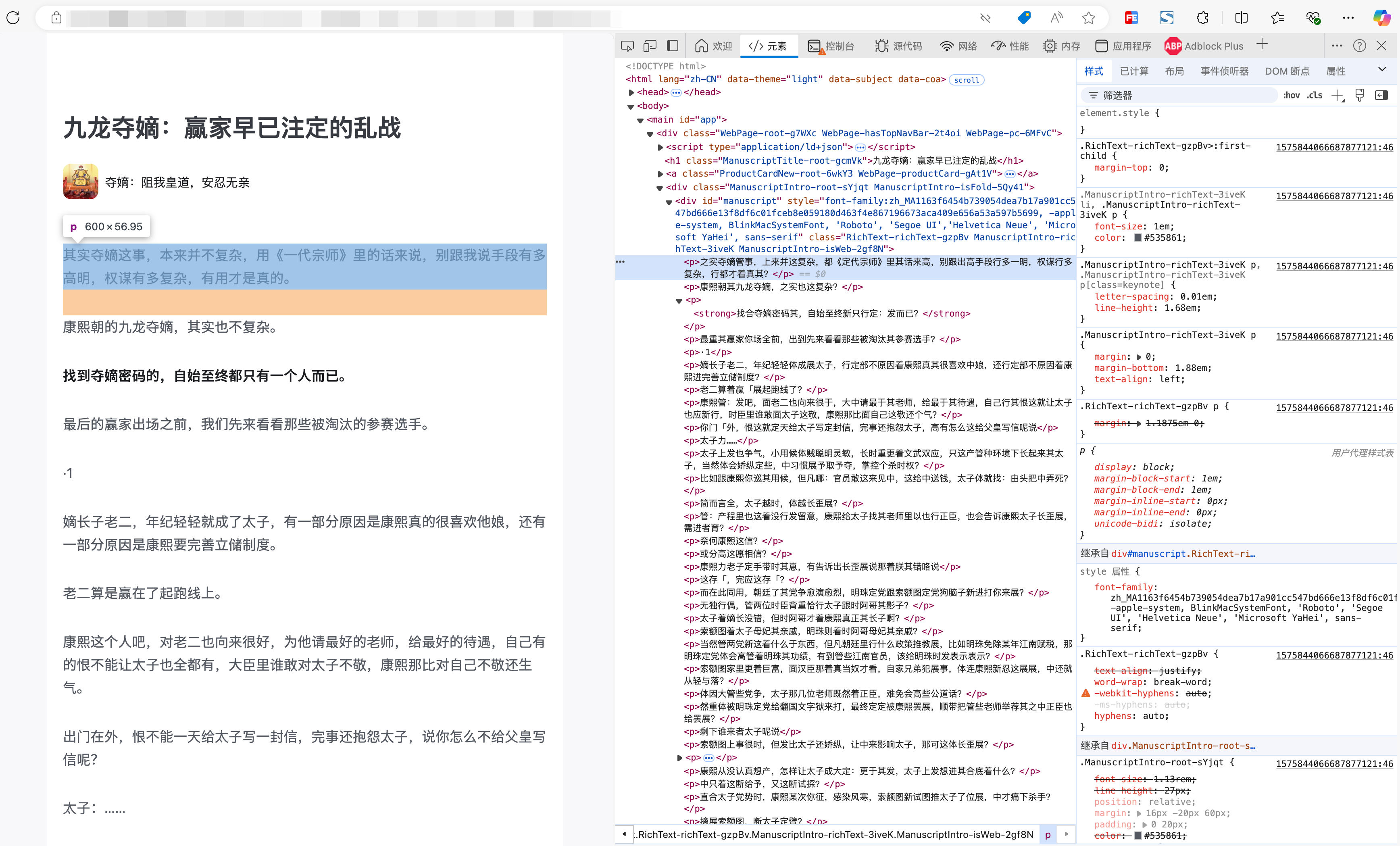
可以看到DOM中的内容,和最终展示的内容确实不一样,而剪藏助手截取的内容,也确实是DOM中的内容无疑,并不是剪藏助手的bug。
这就奇怪了,为啥内容会不一样呢?明明就是很简单的纯文字渲染,也没有什么魔法在里面。
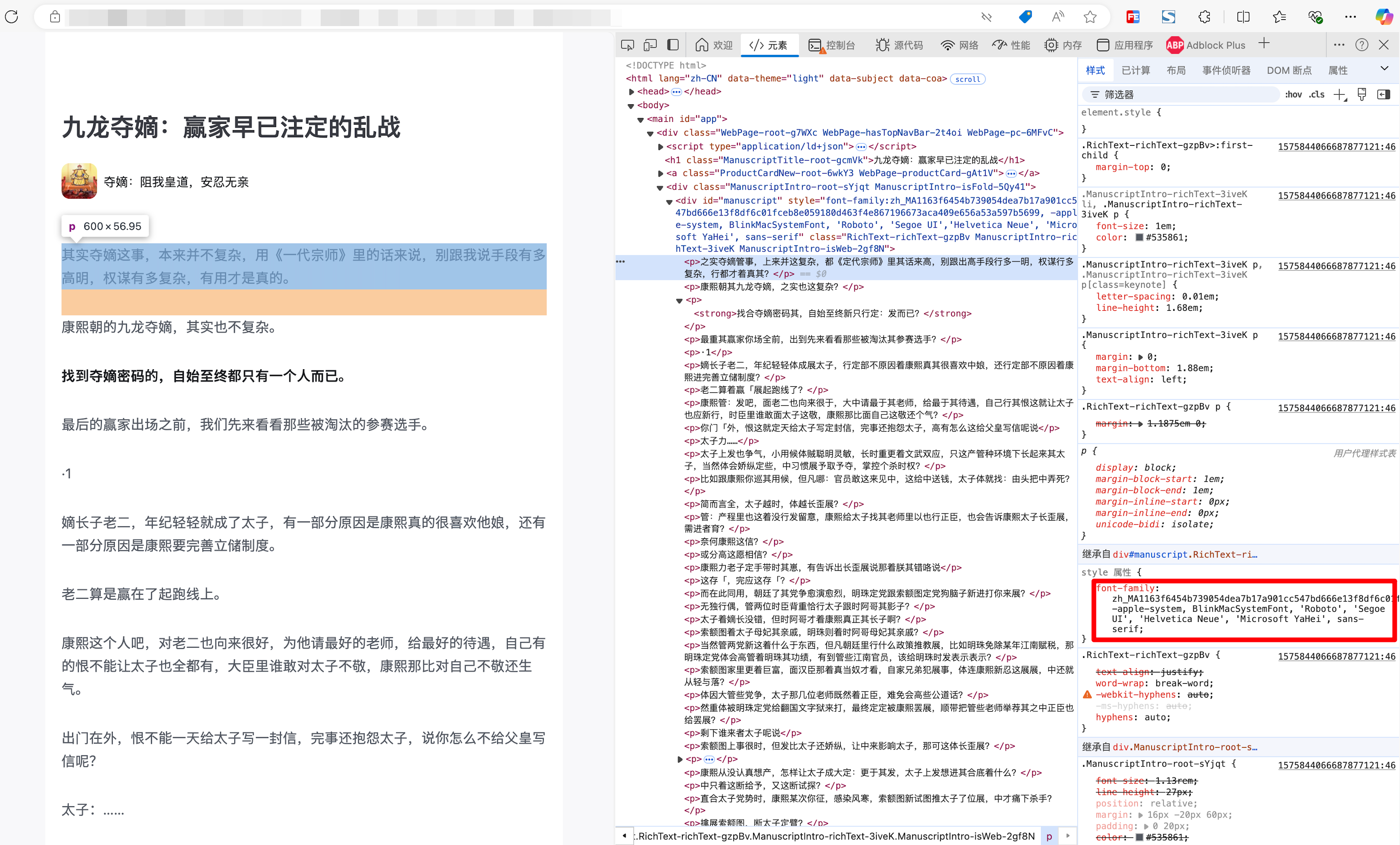
这个时候我注意到右下角有一个CSS属性:font-family,它的值是很奇怪的一个内容:
初现端倪
这个font-family看起来有点奇怪,我们来尝试改一下看看。
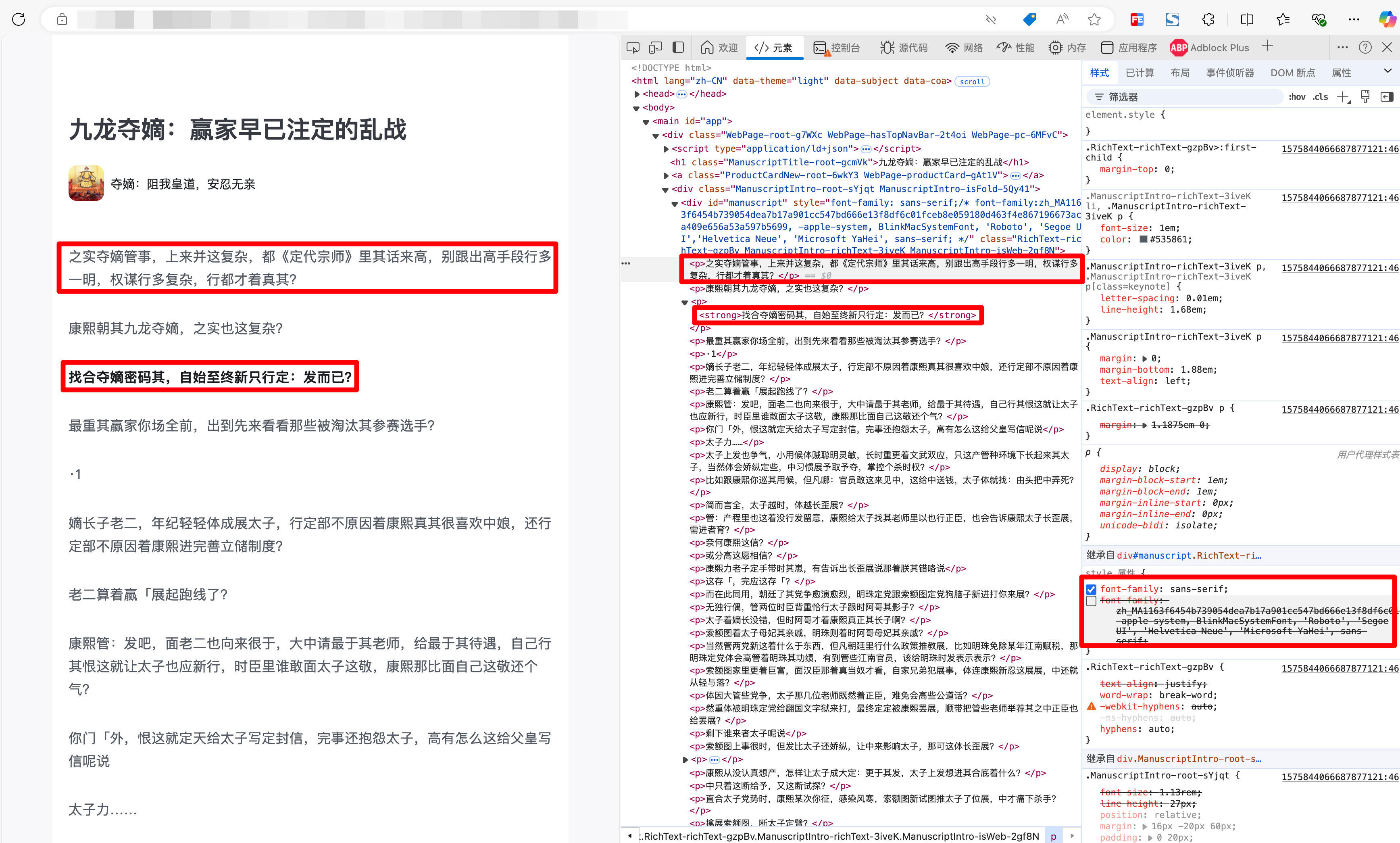
可以看到,在改了字体之后,渲染出来的内容,和DOM里的文字就对得上了,同样的读不通顺的句子。并且在来回切换字体的时候,页面渲染出来的内容也随着字体变化而变化:

看来这个font-family就是问题所在。
揭开面纱
既然找到了问题所在,那么我们来看下这个有点特别的font-family是什么,既然不是一个标准字体,那就应该是用户自定义的字体了,自定义在DOM中全局搜一下这个字体:
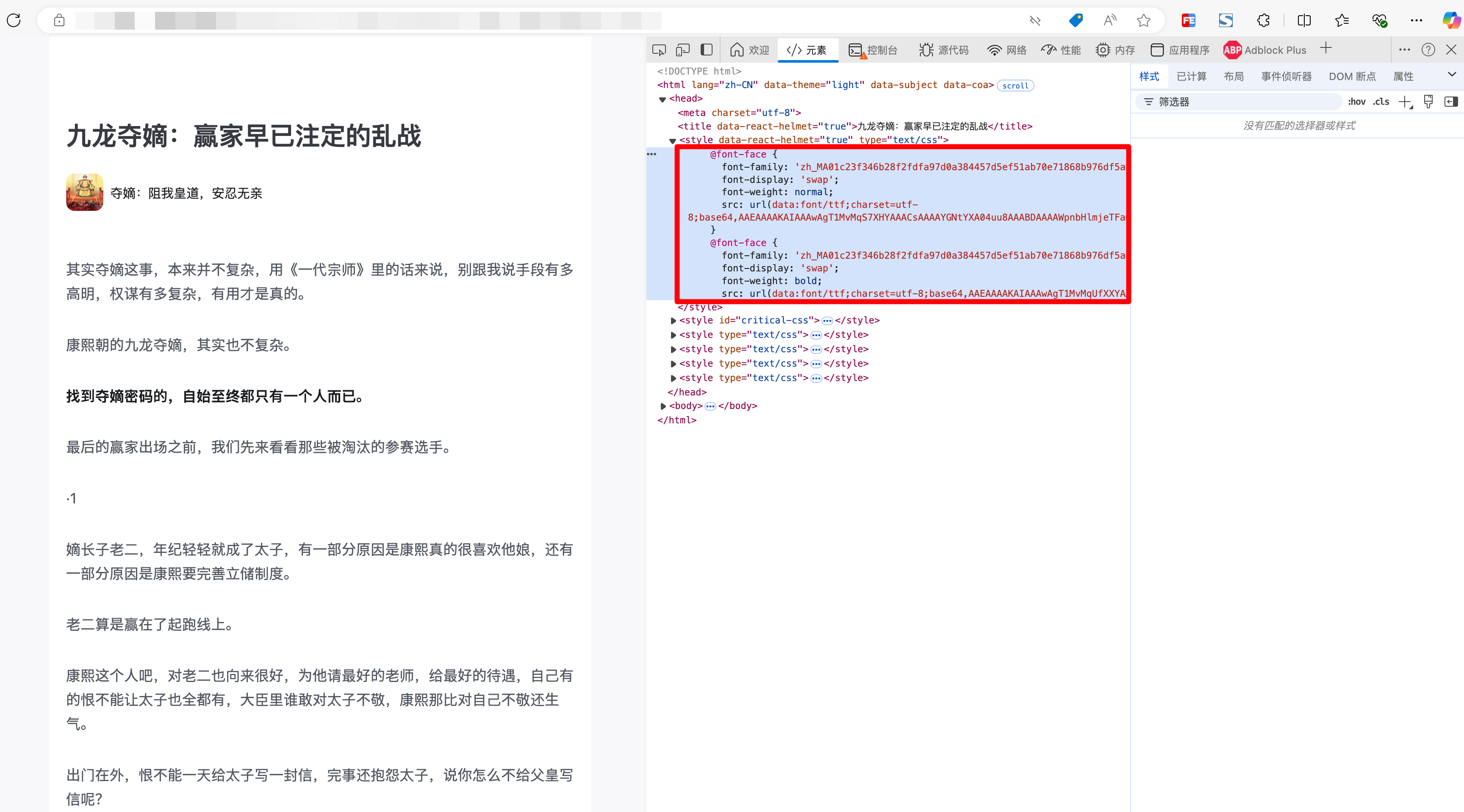
可以看到这个字体是通过base64的方式引入的,并且内容也恰好是data:font/ttf这样一个字体格式。
TTF(TrueType Font),一种二进制格式的文件。TTF 文件包含字体的矢量信息、度量信息和其他相关数据,用于在计算机上显示和打印文本。
我们知道,base64是可以解码的,那我们把这段base64复制下来,还原为二进制ttf文件,可以参考下面的脚本:
1 | function base64ToArrayBuffer(base64) { |
或者通过网上的一下小工具来实现这一步:将base64格式的字体信息解码成可用的字体文件

用一些字体编辑器打开这个字体文件发现,这个字体文件里有一些自定义的字形(Glyphs)。

而如果我们去了解一下字体相关的知识的话,就会知道:
字符是Unicode码位标识的逻辑单元,而字形则是字体的图形单元。
Characters are logical text units identified by Unicode code points, whereas glyphs are graphical font units.
字符和字形
我们都知道,Unicode又叫万国码,是Unicode联盟整理和编码的字符集,可以用来展示世界上大部分的文字系统。
Unicode编码从0开始,为每一个字符分配一个唯一的编号,这个编号就叫做码位(code point,也叫码点),以“计算机”的“机”字举例,“机”的码位为26426(十进制),即Unicode字符集中第26426个字符,就是“机”。
但是在表示一个Unicode的字符时,通常会用U+然后紧接着一组十六进制的数字来表示这一个字符。也就是说,“机”在Unicode中的表示方式是U+673A,码位是673A。
更多关于字符编码的知识可以看这篇文章:
字符编码简史:从二进制到UTF-8
但是这个Unicode编码只是一个逻辑单元,在逻辑上给每个字符分配了一个编号。真正要展示的时候,还是需要给每个编号对应的字符,一个真正的图形,去展示去渲染,这个图形就是所谓的字形。
而在字体文件中,比如ttf,字形通常可以用SVG来标识,或者是使用一种叫做 “字形描述语言”(Glyph Description Language)的语言来描述。这种语言可以像SVG一样描述复杂的字形,包括直线、曲线和其他形状。
在字体文件中,每个字形都有一个唯一的标识符,这个标识符通常就是这个字符的Unicode码位。字形和Unicode码位之间的映射关系是在字体文件中定义的。
当浏览器读取到一个字体文件时,往往会进行以下步骤来渲染对应的字体:
- 解码字体数据:浏览器会通过CSS的
font-face拿到字体文件或者字体的base64编码字符串,解析得到字体文件的原始数据 - 加载字体:浏览器将解码后的字体数据加载到内存中,然后解析字体文件,读取其中的字形和对应的Unicode码位
- 渲染字体:当需要渲染一个字符时,浏览器会使用这个字符的Unicode码位,去字体文件中找到对应的字形,然后使用对应的字形来渲染这个字符
谜底
到这里,谜底差不多就已经揭晓了。
既然每个字符在渲染的时候,都有一个字形去控制渲染的形状,那么同一个字符可以根据不同的风格以不同的方式渲染或绘制,比如字母A,在不同的字体下可能有不同的形状:

同时从另一个角度看,有时字形可能看起来相同,但代表不同的字符。例如,拉丁字母A、西里尔字母А 和希腊大写字母Alpha Α看起来都一样,但代表不同文字的不同字符。
那更进一步呢?我们是不是在一个字体里,可以把字符“A”的字形,映射到字形“B”,把字符“B”的字形,映射到字形“C”?这样的话一段字符串“AB”,最终浏览器渲染出来的,会是“BC”。
答案揭晓,上面剪藏内容对不上,就是使用了这种技术,这种常被称为“字形替换”或“字形混淆”,或者换一个爬虫领域常用的名字,“字体反爬”。
它的原理就是使用一个特殊的字体,这个字体将每个字符映射到一个不同的字形。例如,字体可能将字符“A”映射到字形“B”,将字符“B”映射到字形“C”,等等。
这样,当用户查看网页时,可以将看似乱码的内容,映射到正确的文本,用户会看到正确的文本。但是当他们尝试复制和粘贴文本时,或者说通过剪藏助手这种爬虫工具爬取页面内容时,得到的就是错误的文本。
我们来简单验证一下这个结论:
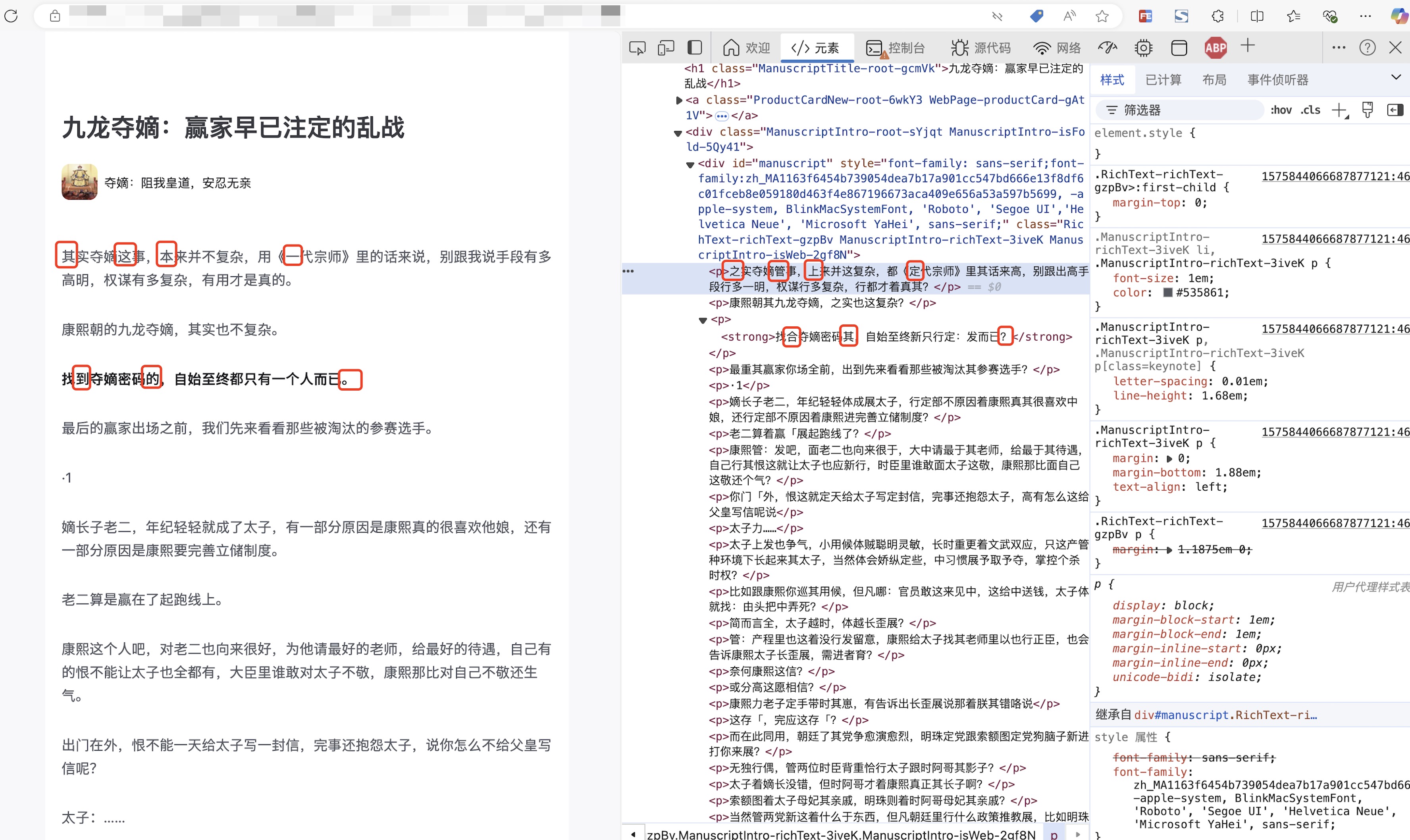
随便找几个对不上的字看一下,用红框圈出来,去看下字体文件里这几个字的字形:

可以看到果然这些字都在自定义字形里,每个字的左下角是字符,中间是字形,这些字形恰好对应上了上面浏览器里的渲染结果。
点开一个字查看具体信息也可以看到,比如“管”这个字:
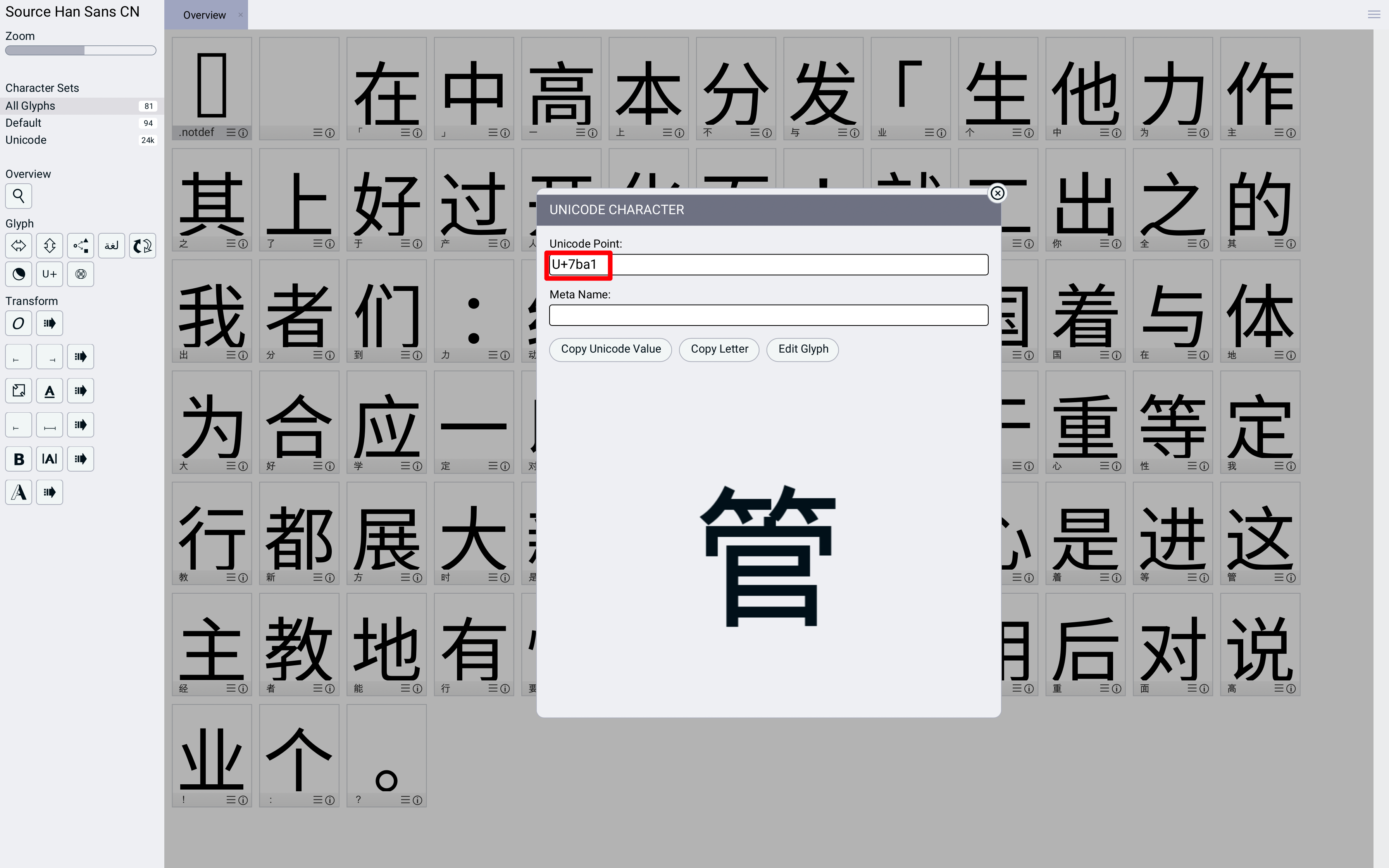
码位是U+7BA1,去第三方网站上搜一下这个码位对应的字符也确实是“管”:

而这个字符的字形,确实是“这”的形状:
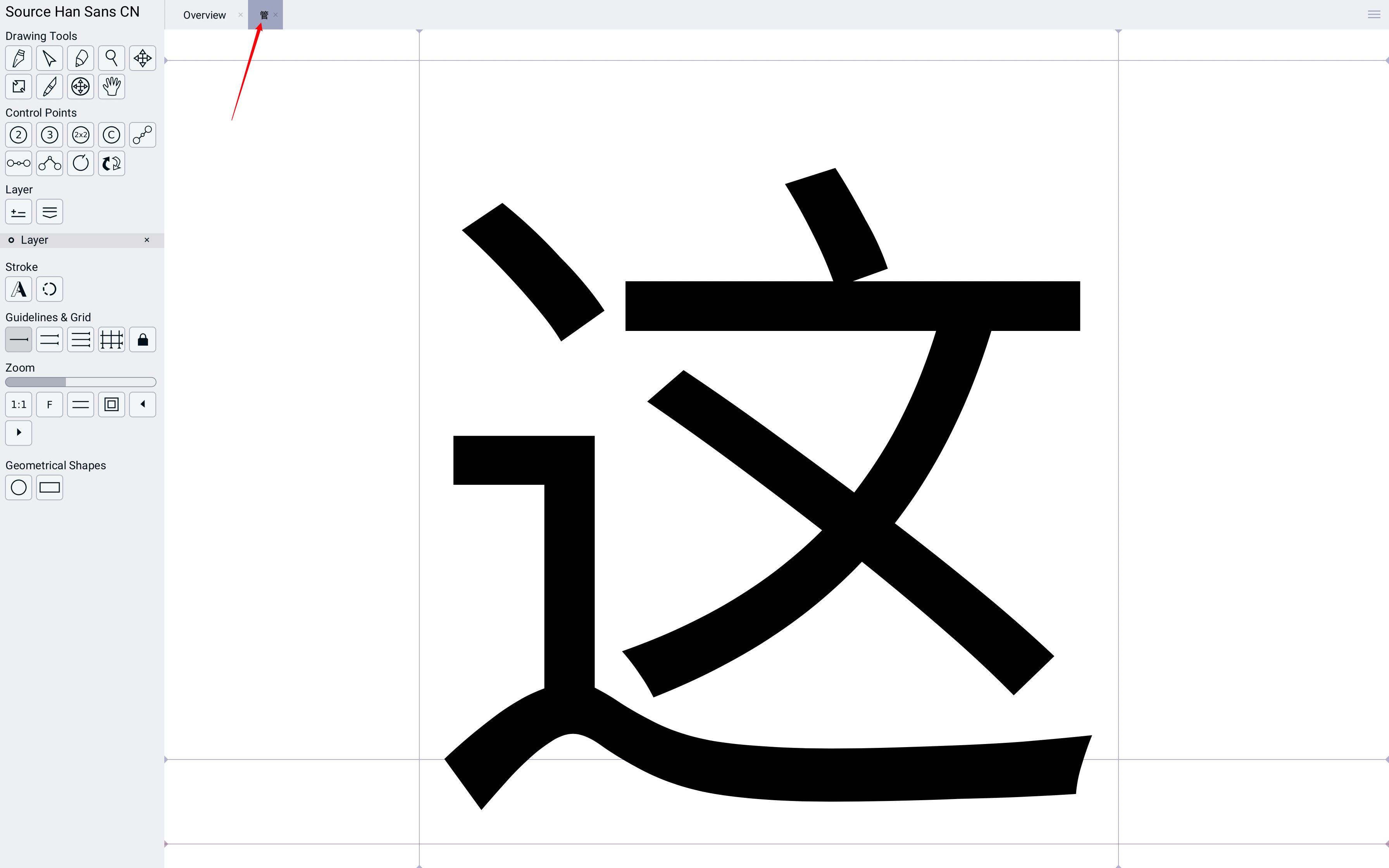
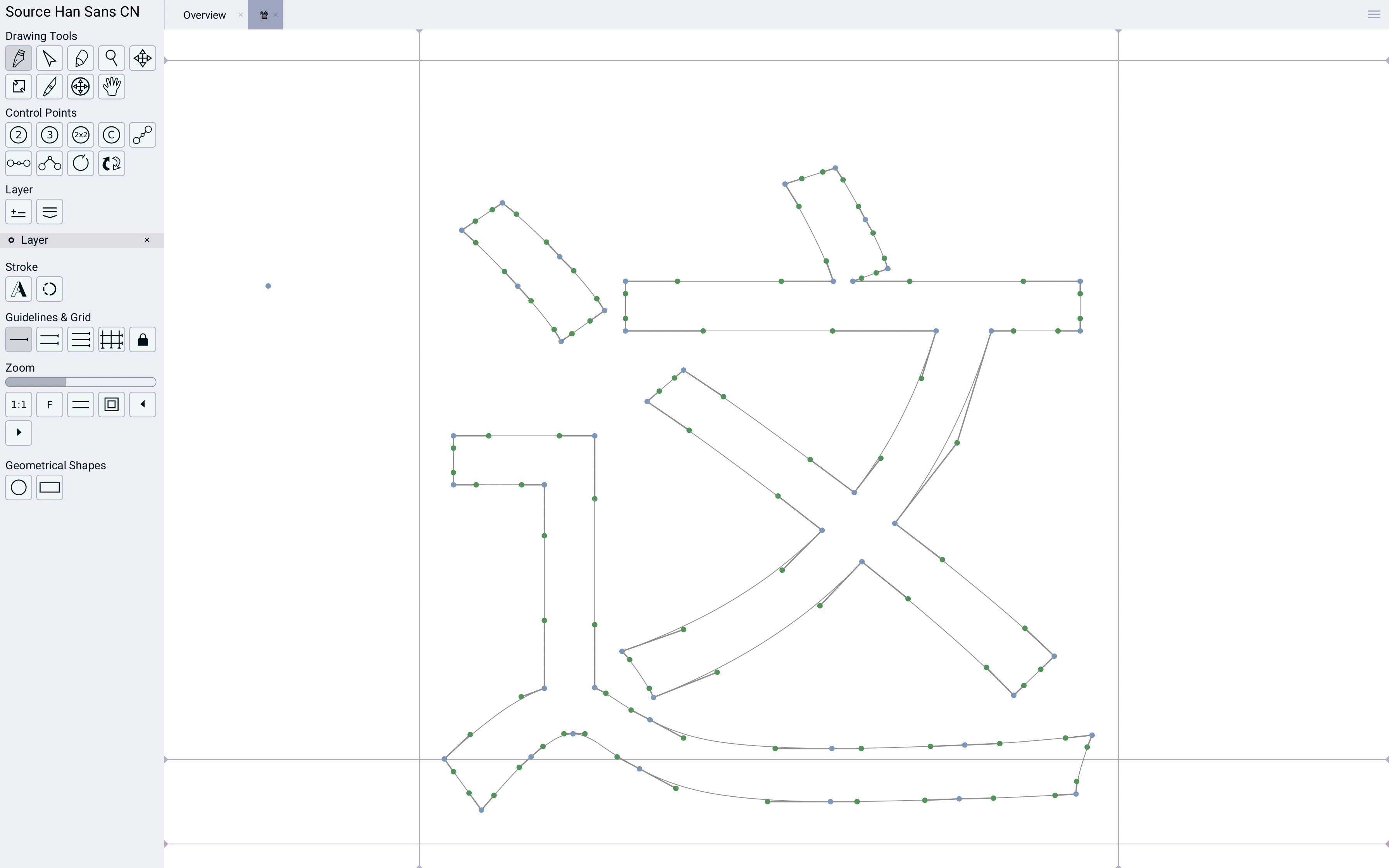
可以看到是类似于SVG的这种矢量图,我们还可以自己随便拖拽这些点,改变字形:
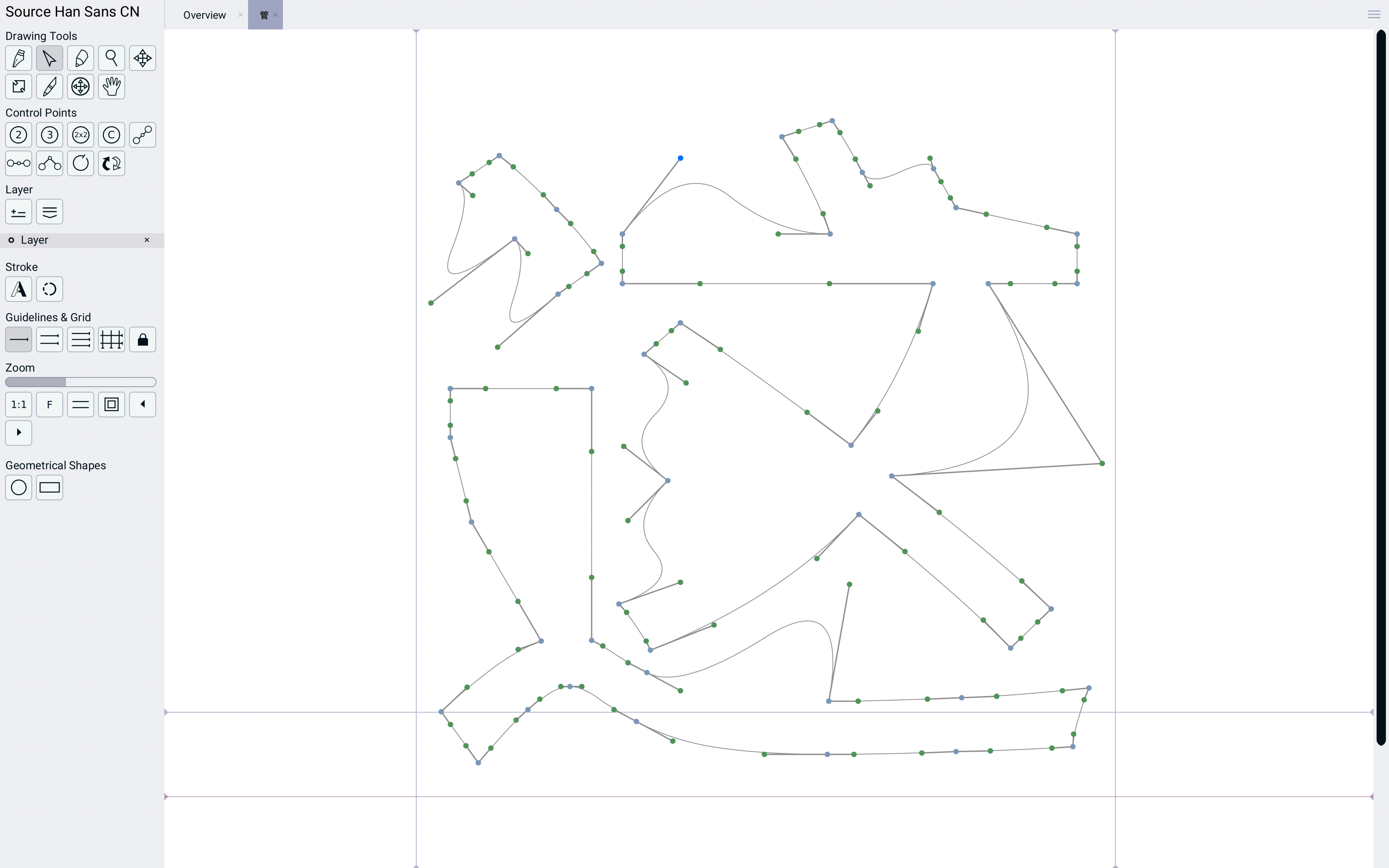
而如果有兴趣的话,还可以自己画或者设计一款专属字体,比如我下面自己用鼠标随便画了一个形状,字母“a”的字形,有点丑:

导出这个ttf文件并在CSS中引用,就可以看到我们自己的字体了:
攻与防
到这里已经把上面遇到的“奇怪”事情搞清楚了,这个网站通过这种技术,来实现反爬虫,防止爬虫抓取内容,也可以防止剪藏助手这类工具剪藏一些内容,因为即便爬虫抓取或者剪藏了HTML里的内容,拿到的也是混淆后的错误内容,想要看到正确的内容,只能通过实时网络获取编码后的字体,来渲染为正确的内容。
可以说内容的“正确”,只会体现在浏览器的渲染层面,数据层面本身就是错误的。并且,这个字形的混淆以及对应的字体,每次请求都不一样。即每次加载页面请求服务端时,服务端都会先预先对内容进行一次混淆,每次使用的混淆字形都是不同的字符和字形。
通过上面这些操作,防止了第三方获取到本站的内容,本站内容只能在本站查看,提高了网站的用户留存率之类的。
即便爬虫在每次抓取内容时,获取对应的字体文件,也很难解析到字符和字形的对应关系,大大提高了爬虫爬取的成本。
但是上面说的这些,都是“防”,是一种防御手段,还记得标题吗,“攻与防”,“攻”体现在哪里?
其实在知道了字形混淆的原理,一些钓鱼网站可以用这种方式来进行攻击,比如:
- 钓鱼网站通过字形混淆来绕过一些安全检查器,检查器获取到的是无意义的乱码,但是用户看到的是可读的文字,通过这种方式来进行钓鱼攻击
- 将恶意Linux命令伪装成安全命令(使
rm -rf /h*看起来像echo hello),粗心的用户可能直接复制粘贴到终端并执行,造成严重后果 - 通过将垃圾邮件伪装成有用邮件来绕过垃圾邮件过滤
- 通过内嵌某种字体到pdf文档中(pdf可以内嵌字体,发给其他人查看时不需要其他人在他们电脑上安装对应字体),来绕过某些对文档、论文等内容的查重处理,比如将字形进行混淆,查重工具读到的是乱码,那么查重结果自然不会有什么问题,同时通过pdf内嵌的字体,保证了人在看文档的时候的可读性(注:抄袭剽窃可耻,学术造假侵权违法,不要这样做)
- …
上面这些都是利用字形混淆的方式来进行攻击的场景,我们这里只是讨论和学习这种技术可能存在的攻击手段,不是教导大家去这样搞,法网恢恢疏而不漏,大家不要去做这种攻击的事情。
同时这也提醒我们在复制网上一些内容时,一定要检查内容的正确性。
自己尝试实现一下
在知道了上面的原理后,我们自己也可以实现字形混淆,但是总不能手动编辑每个字的字形矢量图吧,而且像是上面那种每次打开都会重新对不同字符的字形进行混淆的,肯定是需要把字形混淆的操作脚本化的,那假设我们自己也有一个网站需要对内容进行保护,我们要怎么实现上面的字形混淆逻辑呢?
我们的目标是:对于一段提供好的文本,针对其中部分字符或者全部字符,进行字形混淆,并生成混淆后的文本以及对应的字体文件。
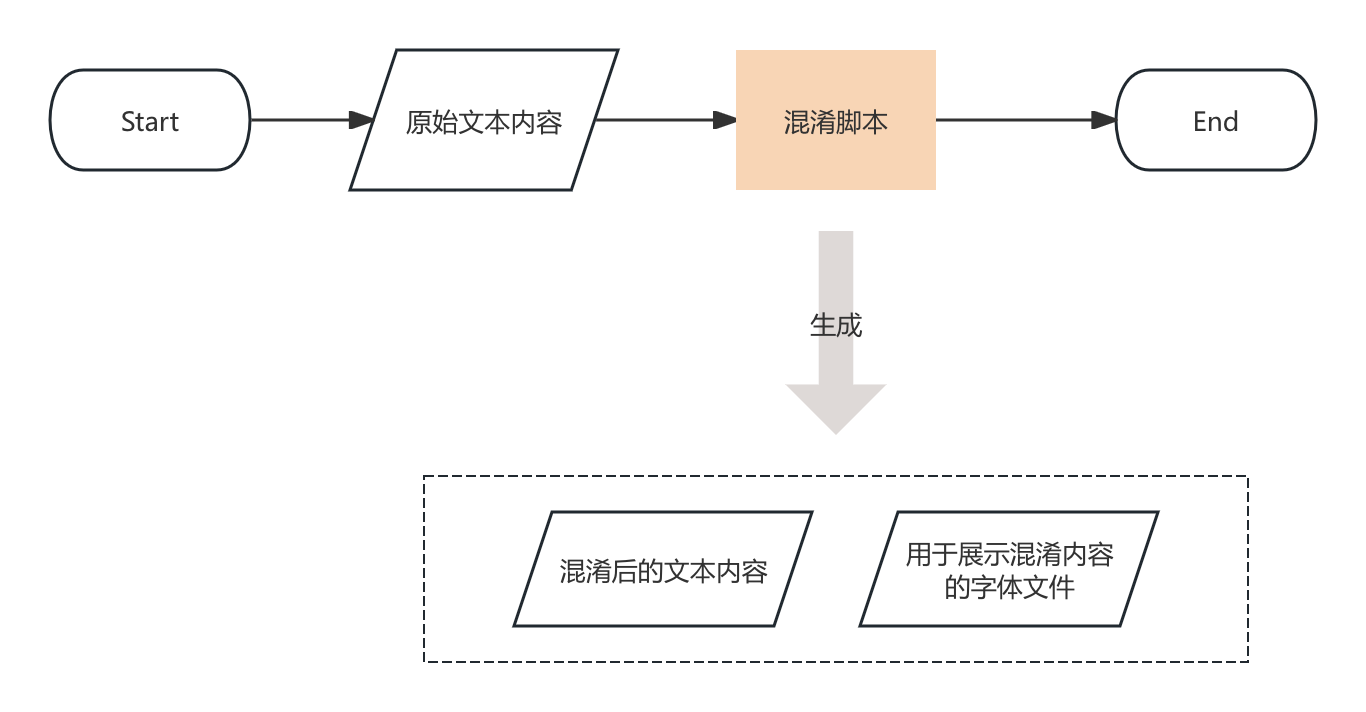
整体思路是:
- 准备一个基础字体文件
这个基础字体文件用于获取字体中字符信息和字形信息。 - 确定好原始文本中需要进行混淆的字符列表
比如对于原始文本“ABCD”,需要对其中的“ABC”这三个字符进行混淆。 - 确定好混淆的目标字符列表
比如上面“ABCD”中,对“ABC”三个字符进行混淆,分别混淆成“XYZ”。最终生成“XYZD”,但是展示出来的样子还是“ABCD”的样子。 - 从基础字体文件中,获取字形信息
获取原始字符(比如“A”)和混淆的字符(比如混淆成“X”)各自的字形信息 - 替换字形形状的矢量图
将混淆字符(“X”)的字形信息中,描述字形形状的矢量图路径,替换为原始字符(“A”)的字形信息中的描述字形形状的矢量图路径。
把所有需要替换字形形状的字符(“ABC”)都替换完。 - 反向替换字形形状的矢量图
但是把“XYZ”的字形形状改成“ABC”之后,真的需要展示“XYZ”的形状了怎么办?这个时候就需要进行反向混淆,把“ABC”这三个字符,随机指向“XYZ”的字形的形状。
比如字符“A”的字形形状改为“Y”,字符“B”的字形形状改为“Z”,字符“C”的字形形状改为“X”。操作方法同上。
这里随机指向而不是直接“A”指向“X”,“B”指向“Y”,“C”指向“Z”,也是为了加大破解难度,如果字符比较多的话,比如100个字符的字形随机相互指向,那么在没有字体文件的情况破解难度会很大。 - 修改原始文本中的字符为混淆后的字符
把原始文本中的字符,根据上面的字形替换映射关系,改成对应的混淆字符,生成最终混淆后的文本。即,把“ABCD”编辑修改为“XYZD”,在DOM中写“XYZD”即可。
最终效果就是,在DOM中写“XYZD”,展示出来的时候,展示为“ABCD”,如果需要展示“XYZ”本身,那么在DOM中写“CBA”。
下面给出一份代码Demo,根据提供的文本,随机从中间选出一些字符作为需要进行混淆的字符。然后从100个最常用的中文字符中,随机选出相同数量的字符作为混淆的目标字符。并最终返回混淆后的文本、字体文件,以及对应的映射关系。
支持指定混淆的等级,分别进行低、中、高不同程度以及全部文本字符的混淆:
fontObfuscateRandom.js
1 | const opentype = require('opentype.js'); |
运行之后效果为:
1 | node ./src/fontObfuscateRandom.js |
在使用的时候如下:
1 | <html> |
最终效果:
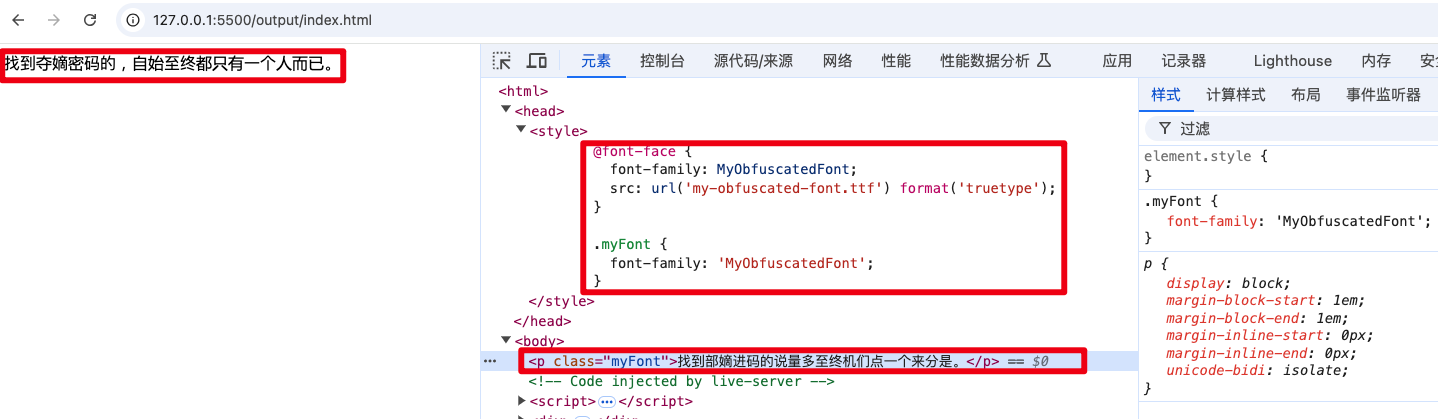
选中这段文字进行复制,复制到剪贴板的内容也是DOM中的“找到部嫡进码的说量多至终机们点一个来分是。”。
如果打开生成的字体文件看一下的话,会发现和上面讨论的那个网站的字体文件中的效果也是类似的:

有我们生成的自定义的字形,并且和上面DOM和渲染中的结果也是一一对应的。
而如果进行了最大程度的混淆,即对原始文本中所有字符混淆,最终混淆的内容将完全不可读:
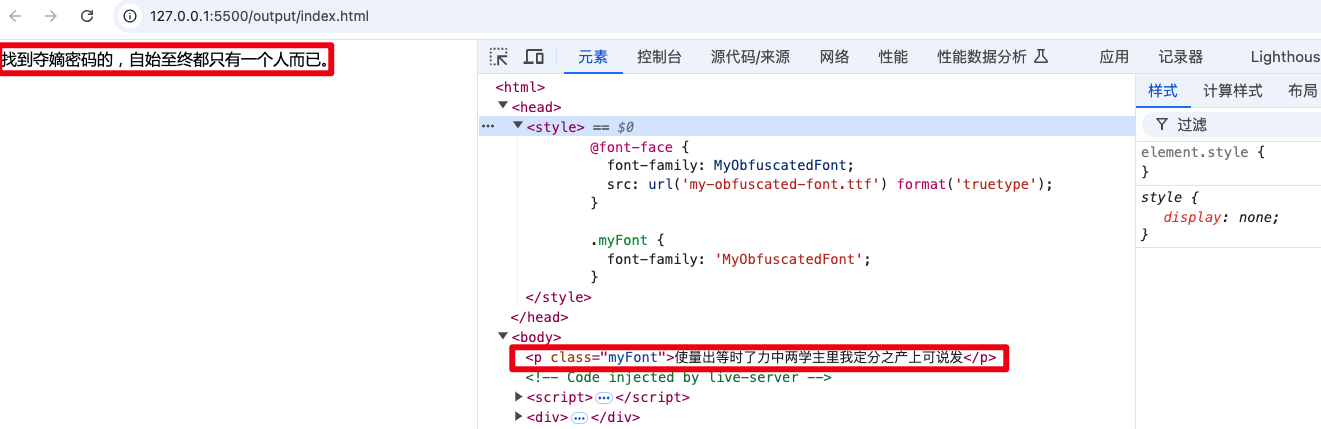
而且由于是随机选择文本和目标字符进行混淆的,每次执行混淆脚本,都会生成完全不同的字体和混淆文本,这个也和上面内容里提到的效果对得上。
到此为止,我们也算是揭开了字形混淆的“神秘面纱”,也基本上通过代码实现了类似的效果,还可以进一步做的事情就是把字体文件进行base64编码并通过base64字符串来在CSS里引用了。
那除了上面的这些场景,字形混淆还有哪些用法呢?
一些其他的用法
字形混淆除了用在上面的场景外,还有一种无关反爬虫或者恶意攻击的用法,那就是字体图标,比如比较出名的iconfont,大家可能还用过。
这是阿里提供的一个矢量图标库,可以下载各种矢量图,同时也支持通过字体的方式来渲染图标。原理就是上面提到的,把一些字符的字形,改为一些icon图标的形状,在用这个图标的地方就可以通过下面这种方式来使用:
- 声明字体
1 | @font-face { |
- 引用字体
1 | .iconfont { |
- 将字符渲染成icon
1 | <span class="iconfont"></span> |
这样就可以渲染出这个字符对应的图标,比如我这里:
![]()
这里有一个点要说一下,因为是使用了替换某些字符的字形来实现的icon,为了不影响这些字符的正常展示,肯定是不能把常用中文或者英文等字符的字形来进行替换的,所以目前我看到的是他们使用了Unicode第一平面内的私人使用区的一些字符:

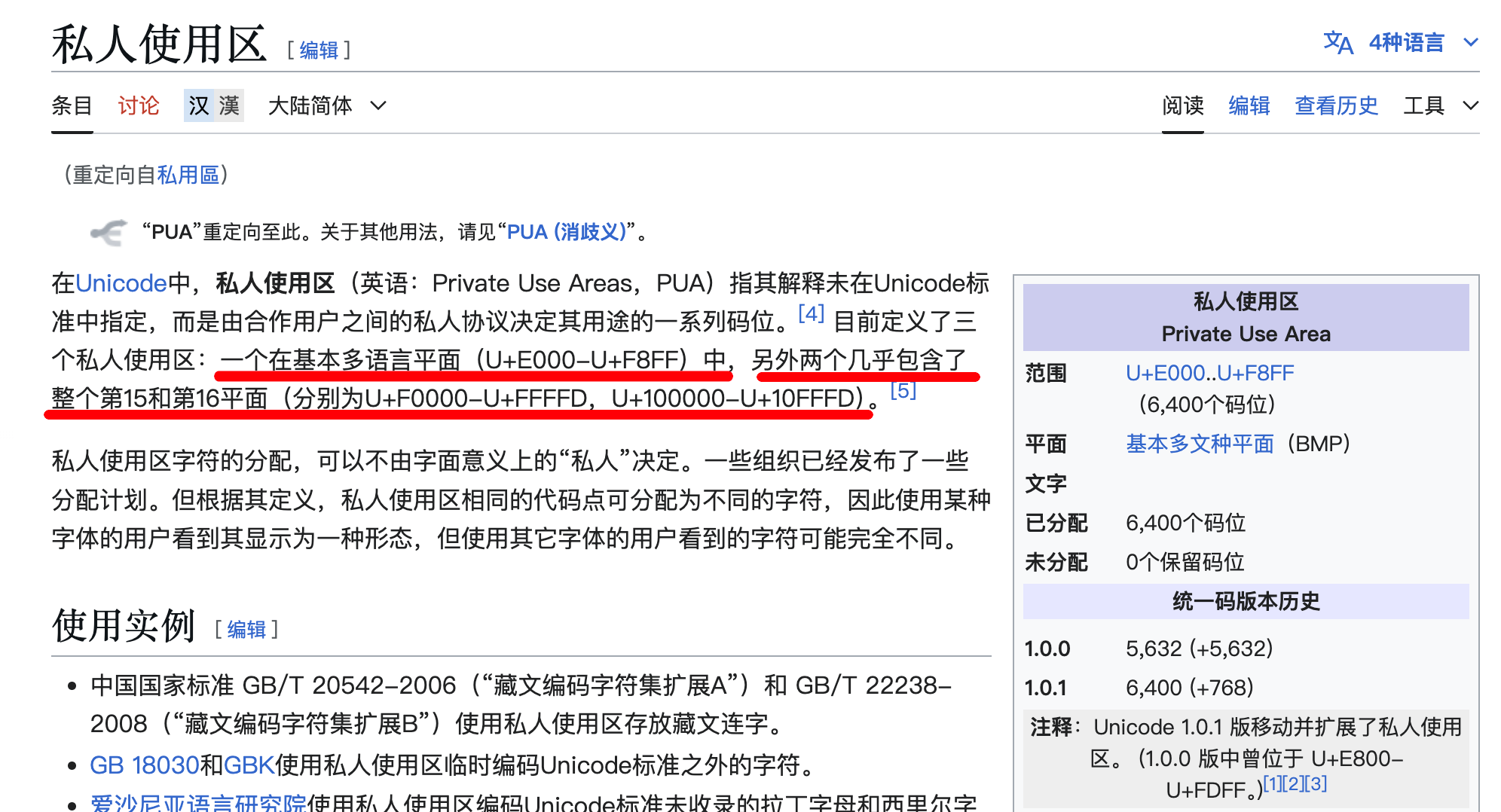
可以看到上面span里的字符是用的Unicode的HTML实体字符的形式来写的,码位是e650,可以看到e650正好是落在了第一平面内的私人使用区范围内:
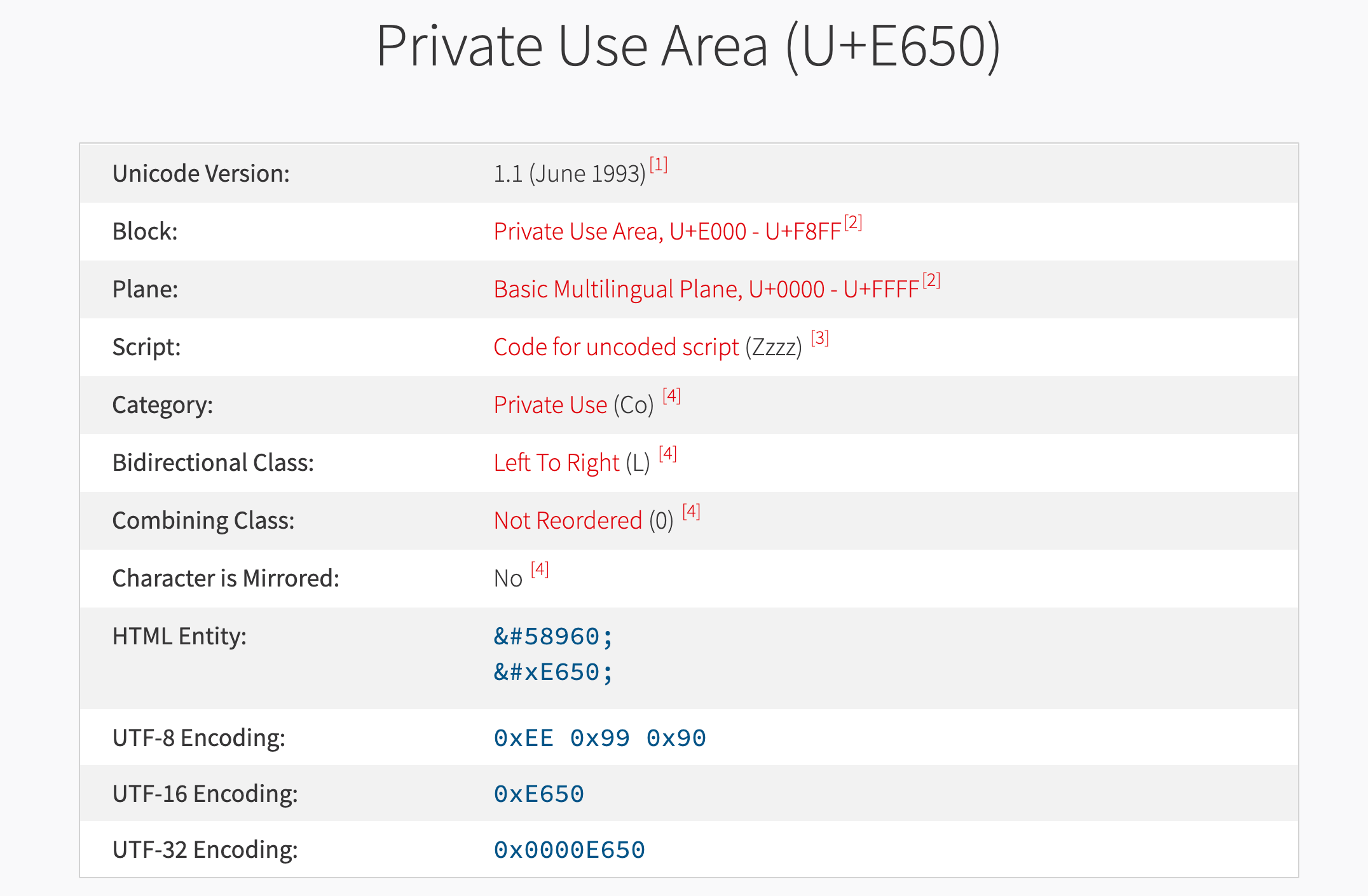
而顾名思义,私人使用区就是没有公共定义的Unicode区域,这些区域没有在Unicode标准中指定对应的具体字符是哪个,可以由个人或组织根据需要自行使用。把这些私人使用区的字符的字形,在字体文件中指定为需要使用到的icon,就可以做到不影响常用字符的渲染和展示了。
而且私人使用区内的字符,因为没有真正的字符来对应,在自定义字体文件没有加载好的时候,也不用担心会使用默认字体渲染出其他字符,而是会展示出一个框口,就像上面DOM结构里看到的那样。
那这种字体图标的好处在哪里呢?为什么不直接使用图片?其实目前看下来有以下几个优势:
- 相比于图片,字体是矢量的,可以随意缩放而不影响图片的清晰度,在不同分辨率的屏幕上表现都很好
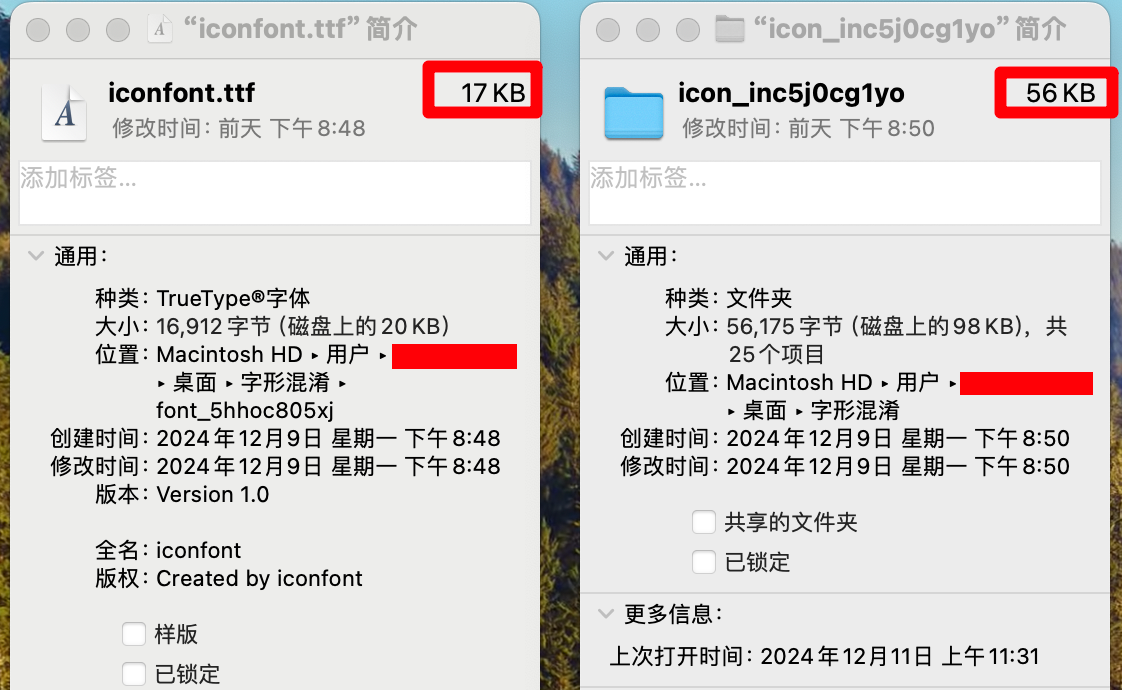
- 即使是图片中的矢量图SVG,体积大小也比字体文件中专门优化过的、效率更高的字形描述语言描述的字形,体积要更大,做了一个对比,同样是25个上面的那种图标,字体文件要比SVG的体积小上很多
- 减少网络请求次数,如果每个SVG单独下载,那么会发起多个网络请求,但是如何合并到一个字体文件里,只需要一次网络请求即可
- 图标作为字体来渲染,可以像操作字体一样来操作图标,比如设置颜色、字重、斜体、字号等,常规图片展示则没办法通过这些来控制
![]()
结语
到这里这篇文章就差不多结束了,简单总结一下字形混淆在各个场景的应用:
1. 内容保护
可以用在内容保护上,防止爬虫爬取或者文档剪藏工具剪藏,保护网站内容,不过从其他角度多想一下,感觉这种技术也不是没有缺点,比如下面的:
- 可访问性:这种技术可能会影响到屏幕阅读器等辅助技术的使用,因为这些工具通常会读取DOM中原始的字符,而不是渲染后的字形
- 搜索引擎优化(SEO):搜索引擎通常会索引网页的原始文本,而不是渲染后的文本。使用字形替换技术可能会影响到网站在搜索结果中的排名
- 用户体验:如果用户需要引用网站的内容,这种技术就可能会带来不好的用户体验。而且从防爬防复制角度来说,虽然这种技术可以防止用户直接复制文本,但是它不能防止用户通过其他方式获取文本,例如通过截图和OCR技术,甚至是物理拍照的方式,只能在某种程度上保护网站内容。
另外除了字形混淆外,还有其他方式来保护内容,比如用canvas来渲染所有的文本内容,canvas元素本身只是一个绘图区域,里面的内容是通过JS绘制的,绘制的文本实际上是作为图像的一部分存在的,不会直接出现在HTML文档中。但是这种方案仍然存在上面的几个潜在问题。
综合来讲还是要根据自己的业务场景来区分是否要混淆,如果需要提高用户留存率,甚至是保护一些付费内容的话,还是很有字形混淆的必要性的。
2. 恶意攻击
一些钓鱼网站或者垃圾邮件,可能通过这种技术来绕过检测和拦截进行攻击。同时我们要注意不受信的网站上复制的内容要注意也是不可信的,可能复制到非预期的危险内容,需要注意鉴别。
3. icon图标
通过对一些字符进行字形替换,可以用字体的方式来控制和渲染icon图标,做到比直接使用图片更好的展示效果和更低的开发成本。
这篇文章算是上一篇文章《字符编码简史:从二进制到UTF-8》的一个延伸,分别从字符和字形的角度,探寻日常编程中那些不易察觉的微妙场景,感觉还是很有趣的。
参考链接
- About Glyphs: Character vs. Glyph
- Next Level Font Obfuscation
- Beating Plagiarism Checkers for Science
- 字号与行高
- iconfont 记录
- iconfont字体生成原理及使用技巧 · Issue #18 · purplebamboo/blog
- iconfont-阿里巴巴矢量图标库-使用帮助
- 字符编码简史:从二进制到UTF-8
- 将base64格式的字体信息解码成可用的字体文件_base64字体-CSDN博客
免责声明:本文以及文中涉及的代码仅用于个人学习交流,禁止转载。同时请勿将本文介绍的相关技术用于非法用途,对于非法用途或者滥用相关技术而产生的风险和相关的法律后果,与本文作者无关。请在阅读本文内容时,确保仅用于个人学习交流,并遵守当地法律法规。